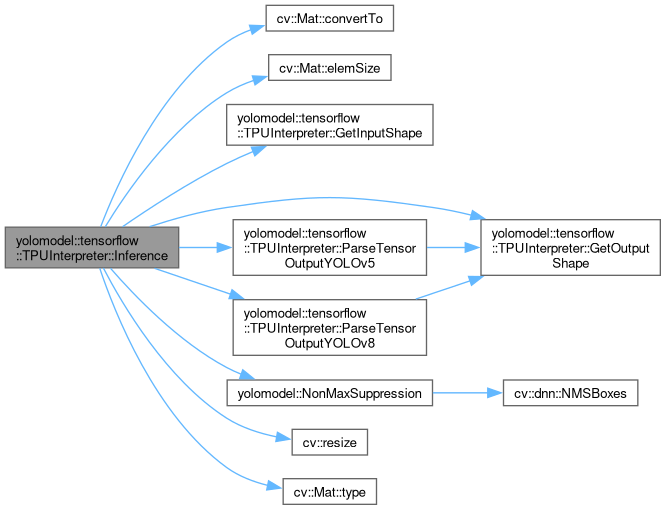
Given an input image forward the image through the YOLO model to run inference on the EdgeTPU, then parse and repackage the output tensor data into a vector of easy-to-use Detection structs.
280 {
281
282 std::vector<std::vector<Detection>> vTensorObjectOutputs;
283
284
285 InputTensorDimensions stInputDimensions = this->
GetInputShape(m_pInterpreter->inputs()[0]);
286
287
288 m_cvFrame = cvInputFrame;
289
290
291 if (m_bDeviceOpened && m_pEdgeTPUContext->IsReady())
292 {
293
294 if (m_cvFrame.
type() != CV_8UC3)
295 {
296
298 }
299
300
301 if (m_cvFrame.
rows != stInputDimensions.nHeight || m_cvFrame.
cols != stInputDimensions.nWidth)
302 {
303
305 m_cvFrame,
306 cv::Size(stInputDimensions.nWidth, stInputDimensions.nHeight),
307 constants::BASICCAM_RESIZE_INTERPOLATION_METHOD);
308 }
309
310
311 std::vector<int8_t> vInputData(m_cvFrame.
data,
312 m_cvFrame.
data + (
static_cast<unsigned long>(m_cvFrame.
cols) * m_cvFrame.
rows * m_cvFrame.
elemSize()));
313
314
315
316
317
318
319
320
321 TfLiteTensor* pInputTensor = m_pInterpreter->tensor(stInputDimensions.nTensorIndex);
322 std::memcpy(pInputTensor->data.raw, vInputData.data(), vInputData.size());
323
324
325 if (m_pInterpreter->Invoke() != kTfLiteOk)
326 {
327
328 LOG_WARNING(logging::g_qSharedLogger,
329 "Inferencing failed on an image for model {} with device {} ({})",
330 m_szModelPath,
331 m_tpuDevice.path,
332 this->DeviceTypeToString(m_tpuDevice.type));
333 }
334 else
335 {
336
337 std::vector<int> vClassIDs;
338 std::vector<float> vClassConfidences;
339 std::vector<cv::Rect> vBoundingBoxes;
340
341 std::vector<Detection> vObjects;
342
343
344 for (int nTensorIndex : m_pInterpreter->outputs())
345 {
346
347 vClassIDs.clear();
348 vClassConfidences.clear();
349 vBoundingBoxes.clear();
350
351 vObjects.clear();
352
353
354
355
356
357 OutputTensorDimensions stOutputDimensions = this->
GetOutputShape(nTensorIndex);
358
359 int nImgSize = stInputDimensions.nHeight;
360 int nP3Stride = std::pow((nImgSize / 8), 2);
361 int nP4Stride = std::pow((nImgSize / 16), 2);
362 int nP5Stride = std::pow((nImgSize / 32), 2);
363
364 int nYOLOv5AnchorsPerGridPoint = 3;
365 int nYOLOv8AnchorsPerGridPoint = 1;
366 int nYOLOv5TotalPredictionLength =
367 (nP3Stride * nYOLOv5AnchorsPerGridPoint) + (nP4Stride * nYOLOv5AnchorsPerGridPoint) + (nP5Stride * nYOLOv5AnchorsPerGridPoint);
368 int nYOLOv8TotalPredictionLength =
369 (nP3Stride * nYOLOv8AnchorsPerGridPoint) + (nP4Stride * nYOLOv8AnchorsPerGridPoint) + (nP5Stride * nYOLOv8AnchorsPerGridPoint);
370
371
372 if (stOutputDimensions.nAnchors == nYOLOv5TotalPredictionLength)
373 {
374
376 vClassIDs,
377 vClassConfidences,
378 vBoundingBoxes,
379 fMinObjectConfidence,
382 }
383
384 else if (stOutputDimensions.nAnchors == nYOLOv8TotalPredictionLength)
385 {
386
388 vClassIDs,
389 vClassConfidences,
390 vBoundingBoxes,
391 fMinObjectConfidence,
394 }
395
396
397 NonMaxSuppression(vObjects, vClassIDs, vClassConfidences, vBoundingBoxes, fMinObjectConfidence, fNMSThreshold);
398
399
400 vTensorObjectOutputs.emplace_back(vObjects);
401 }
402 }
403 }
404 else
405 {
406
407 LOG_WARNING(logging::g_qSharedLogger,
408 "Inferencing failed on an image for model {} with device {} ({})",
409 m_szModelPath,
410 m_tpuDevice.path,
411 this->DeviceTypeToString(m_tpuDevice.type));
412 }
413
414 return vTensorObjectOutputs;
415 }
void convertTo(OutputArray m, int rtype, double alpha=1, double beta=0) const
OutputTensorDimensions GetOutputShape(const int nTensorIndex=0)
Get the output shape of the tensor at the given index. Requires the device to have been successfully ...
Definition YOLOModel.hpp:659
InputTensorDimensions GetInputShape(const int nTensorIndex=0)
Get the input shape of the tensor at the given index. Requires the device to have been successfully o...
Definition YOLOModel.hpp:622
void ParseTensorOutputYOLOv5(int nOutputIndex, std::vector< int > &vClassIDs, std::vector< float > &vClassConfidences, std::vector< cv::Rect > &vBoundingBoxes, float fMinObjectConfidence, int nOriginalFrameWidth, int nOriginalFrameHeight)
Given a TFLite output tensor from a YOLOv5 model, parse it's output into something more usable....
Definition YOLOModel.hpp:448
void ParseTensorOutputYOLOv8(int nOutputIndex, std::vector< int > &vClassIDs, std::vector< float > &vClassConfidences, std::vector< cv::Rect > &vBoundingBoxes, float fMinObjectConfidence, int nOriginalFrameWidth, int nOriginalFrameHeight)
Given a TFLite output tensor from a YOLOv8 model, parse it's output into something more usable....
Definition YOLOModel.hpp:544
void NonMaxSuppression(std::vector< Detection > &vObjects, std::vector< int > &vClassIDs, std::vector< float > &vClassConfidences, std::vector< cv::Rect > &vBoundingBoxes, float fMinObjectConfidence, float fNMSThreshold)
Perform non max suppression for the given predictions. This eliminates/combines predictions that over...
Definition YOLOModel.hpp:71

 Public Member Functions inherited from
Public Member Functions inherited from